Claude Sonnet 4.6, Claude Opus 4.6, Claude 4.6 Sonnet (Reasoning), Gemini 3.1 Pro, GPT 5.2, and Mistral Large 3 are now available in Playlab!What is this feature?
You can now build on top of even more LLMs in Playlab! There are now over 15 available AI models for you to build your Playlab apps on top of. We will try our best to always provide the latest models for you to build on top of.Rationale for the feature
This feature allows Playlab users to experiment with and leverage the unique strengths of various AI models from different providers all within Playlab. As you build, you might find that certain models perform better at different tasks. This will allow Playlab users to select the model that fits their needs better. The more available models, the more likely you are to find one that meets your needs. We believe that Playlabbers should have access to frontier models as we build in community.Understanding Model Types
Before selecting a model, it’s helpful to understand the different categories of AI models available:| Frontier Models | Open Weight Models | Open Source Models |
|---|---|---|
| Cutting-edge, proprietary models developed by major AI companies | Models with publicly available parameters (weights) that can be downloaded and run independently | Fully open models where both weights and training code are publicly available |
| Typically offer the most advanced capabilities and are continuously updated with the latest research breakthroughs | While training code may not be available, you have more control over deployment and customization | Offer maximum transparency and customization potential |
| Examples: Claude Opus 4.6, Claude Sonnet 4.6, GPT 5.2, GPT-5 Mini, Gemini 3.1 Pro, Gemini 3 Flash | Examples: Llama models, DeepSeek R1, GPT OSS 120B, Kimi K2.5, Qwen 3, Mistral Large 3 | Coming soon! |
How do I access these models?
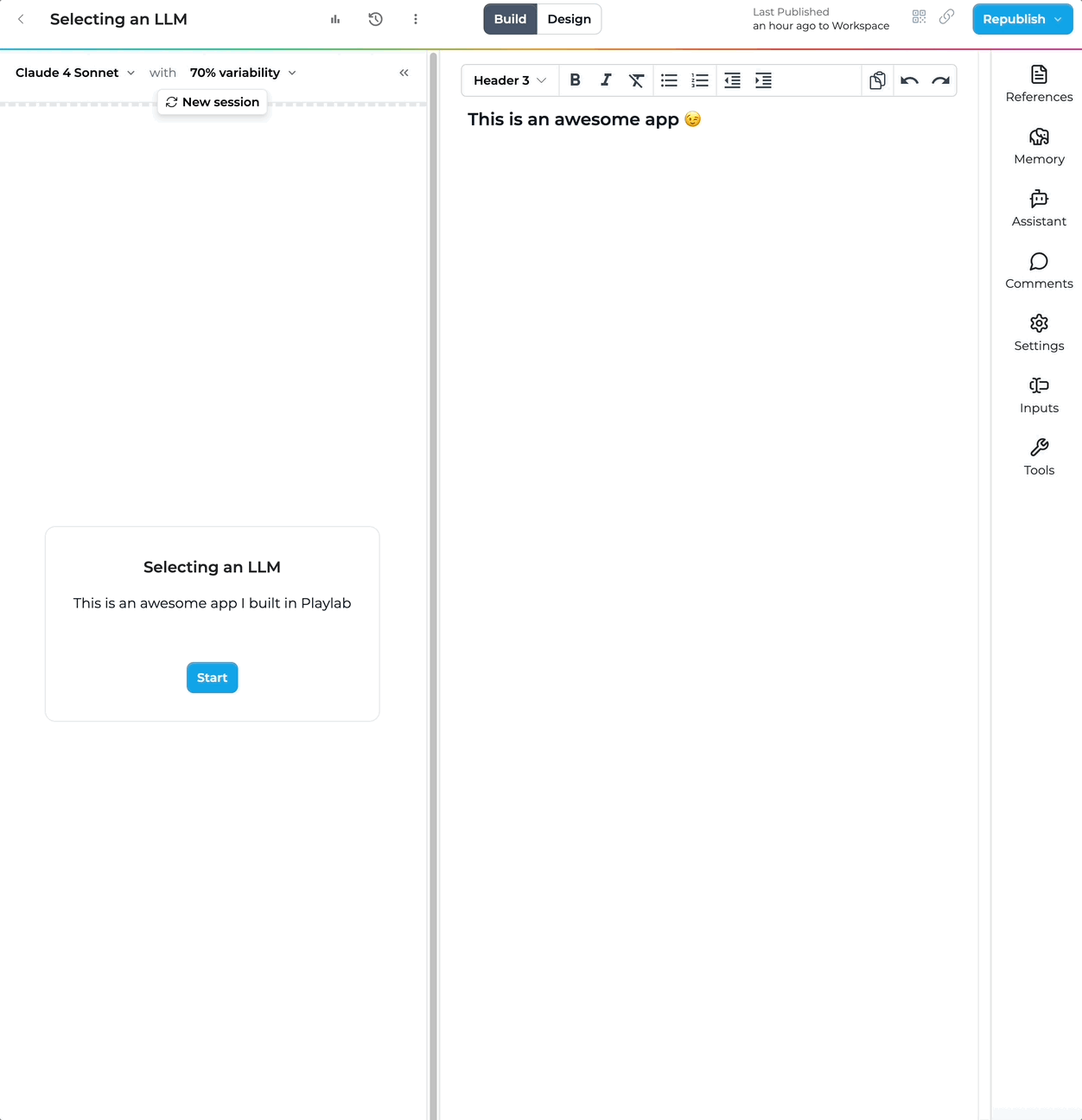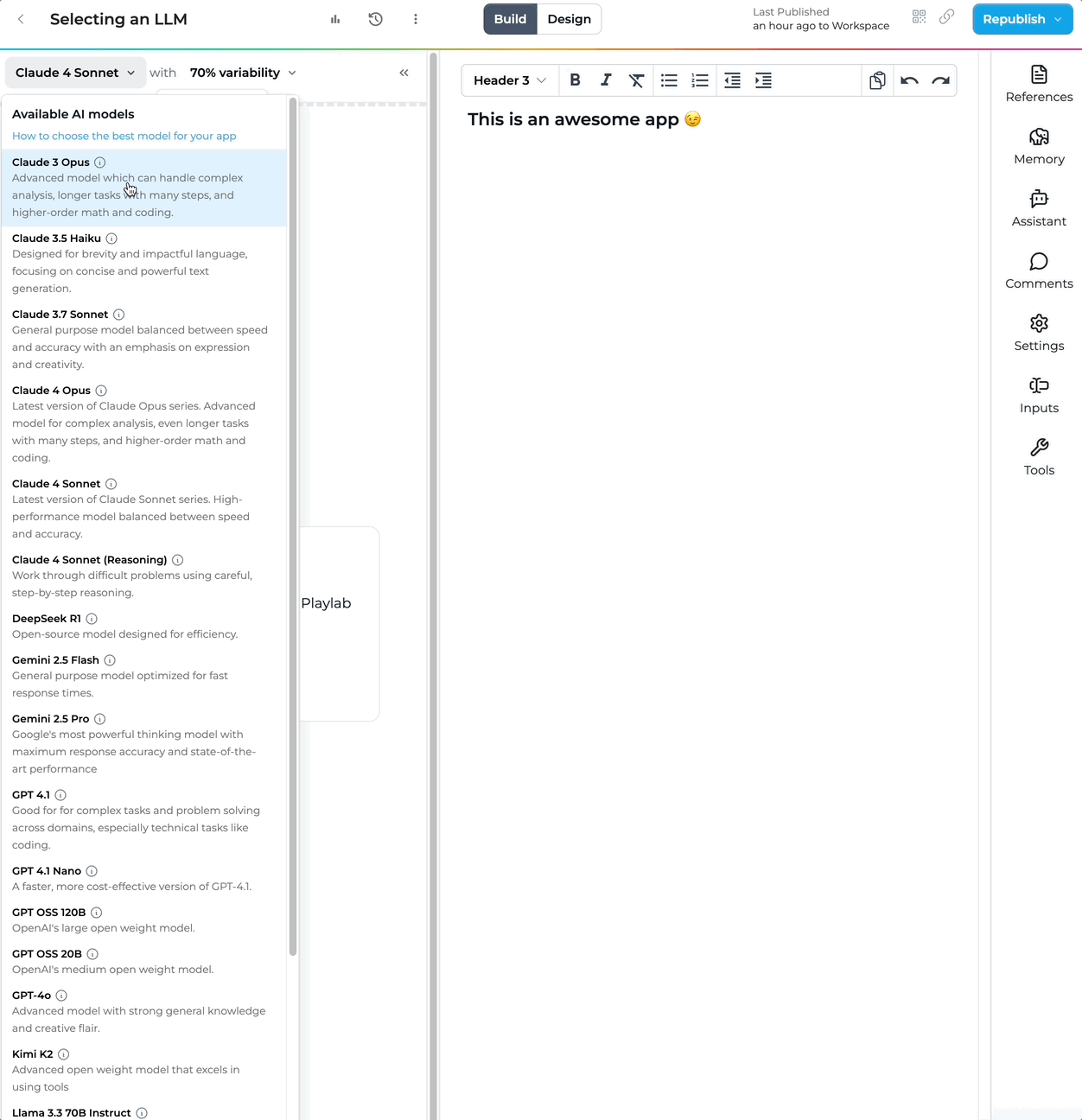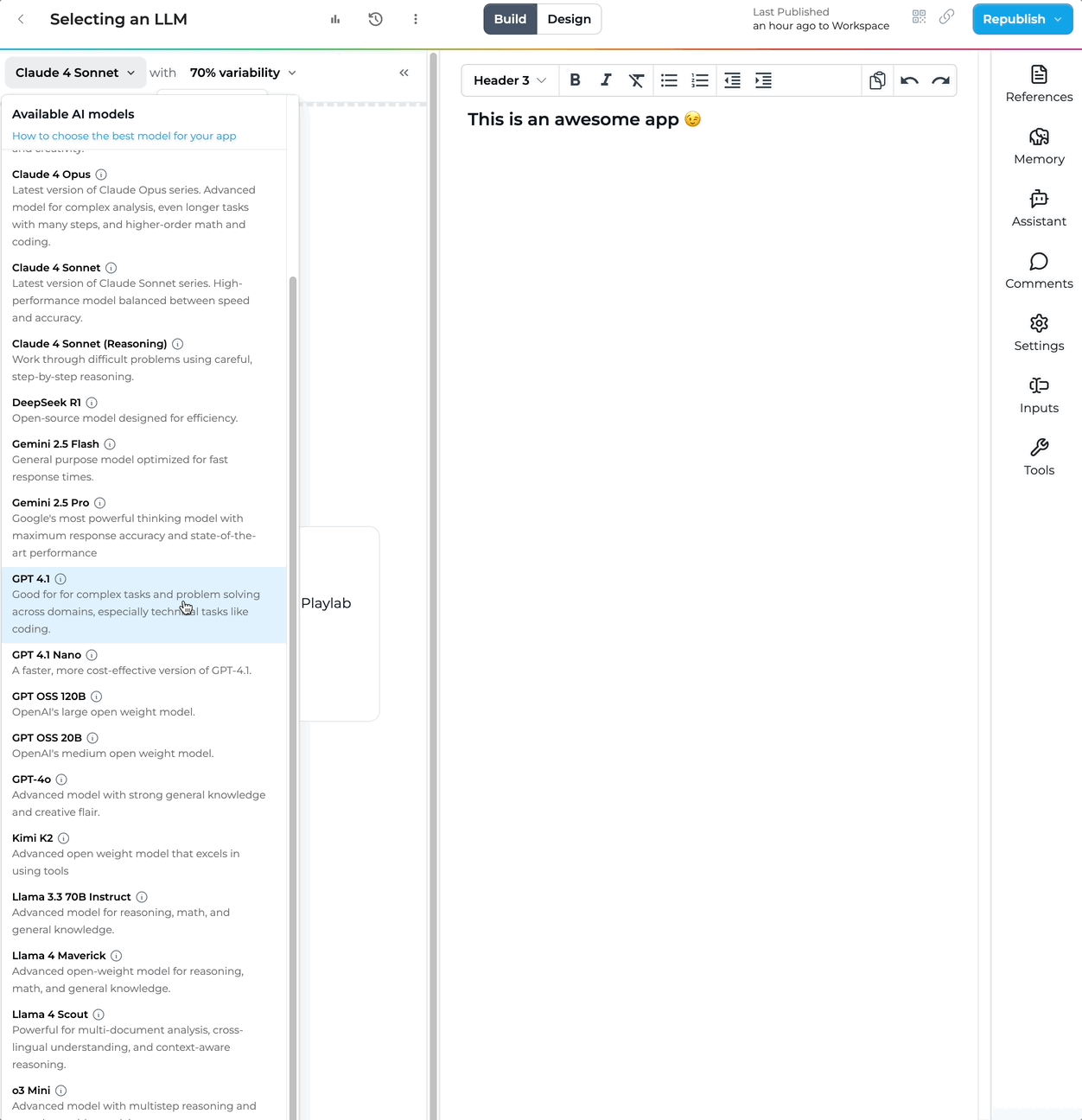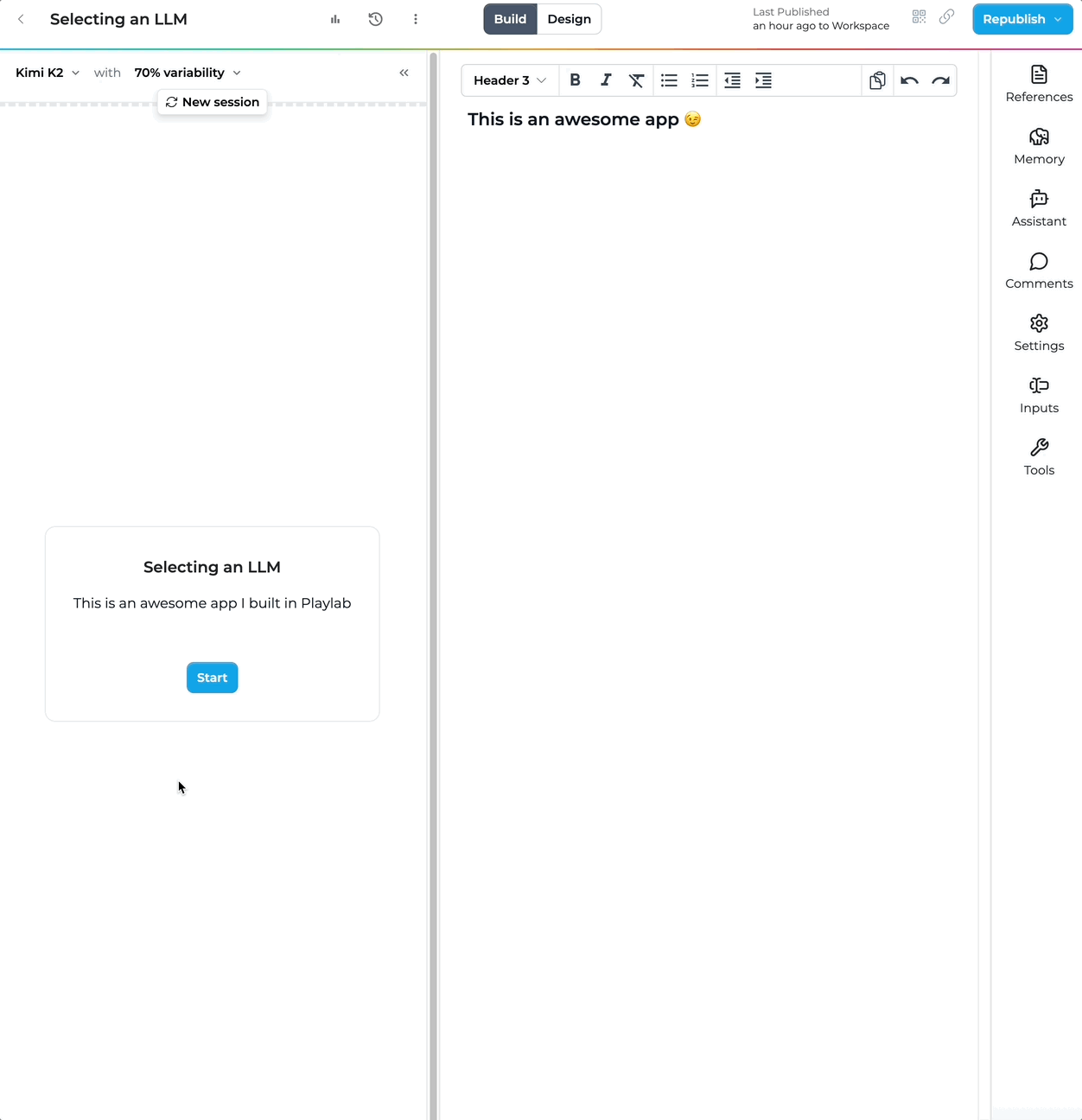
Choose your model
Which models should I use?
Now that you know how to select models, here are some strengths and tradeoffs of each:Claude Opus 4.6 (Anthropic)
Description: Advanced model for complex analysis, even longer tasks with many steps, and higher-order math and coding.
Strengths: Unmatched intelligence and reasoning depth. Superior performance on complex multi-step problems. Exceptional analytical and coding capabilities. Best-in-class for higher-order math and extended tasks.
Trade Offs: Slower response times and higher cost. Best reserved for tasks that truly require maximum capability.
Claude Sonnet 4.6 (Anthropic)
Description: Latest version of Claude Sonnet series - with the highest intelligence across most tasks.
Strengths: Highest intelligence across most tasks. Superior instruction following and nuance understanding. Exceptional balance of speed and capability. Best-in-class for most applications requiring high quality output.
Trade Offs: More expensive than smaller models. May be more than needed for very simple tasks.
Claude Haiku 4.5 (Anthropic)
Description: Near-frontier intelligence at blazing speeds with extended thinking and exceptional cost-efficiency.
Strengths: Blazing fast response times with extended thinking capabilities. Near-frontier intelligence at exceptional cost-efficiency. Excellent for quick questions and lightweight tasks.
Trade Offs: Less capable than Sonnet or Opus models. May struggle with complex multi-step reasoning and advanced analysis.
Claude 4.6 Sonnet (Reasoning) (Anthropic)
Description: Work through difficult problems using careful, step-by-step reasoning.
Strengths: Exceptional step by step reasoning capabilities. Stronger at math and coding. Very good at explaining thought process.
Trade Offs: Slower response times. Not as optimized for creative tasks. Consider Claude Sonnet 4.6 or Claude Opus 4.6 for better overall performance.
GPT 5.2 (OpenAI)
Description: OpenAI’s latest coding and reasoning model.
Strengths: State-of-the-art coding and reasoning performance. Exceptional problem-solving capabilities. Superior instruction following and nuance understanding.
Trade Offs: Slower response times and higher cost. May be unnecessary for simple tasks. Premium pricing for cutting-edge capabilities.
GPT-5 Mini (OpenAI)
Description: Faster model for well-defined tasks.
Strengths: Fast response times for well-defined tasks. Cost-effective for regular applications. Strong performance across most tasks without premium overhead.
Trade Offs: Slightly reduced capabilities compared to GPT 5.2. May not excel at the most complex reasoning challenges requiring maximum model capacity.
GPT OSS 120B (OpenAI)
Description: OpenAI’s large open weight model.
Strengths: Open weights allow for customization and local deployment. Strong general capabilities. Good for research and experimentation.
Trade Offs: Requires significant computational resources. May not match latest frontier model performance.
Gemini 3.1 Pro (Google)
Description: Google’s most powerful thinking model with maximum response accuracy and state-of-the-art performance.
Strengths: Maximum response accuracy and state-of-the-art performance. Exceptional reasoning and problem-solving. Superior performance on complex analytical tasks. Enhanced creative and coding capabilities. Best-in-class for applications requiring advanced Google AI.
Trade Offs: Slower response times compared to Flash models. Higher cost for premium capabilities. May be unnecessary for simple tasks.
Gemini 3 Flash (Google)
Description: General purpose model optimized for fast response times.
Strengths: Extremely fast response times. Strong general-purpose performance. Good for simple instruction following and high volume tasks.
Trade Offs: Not ideal for multi-step problem solving or complex instruction following. May miss nuance in instructions.
Gemini 2.5 Flash (Google)
Description: Previous version of Google’s general purpose model optimized for fast response times.
Strengths: Extremely fast response times. Good for simple instruction following and high volume tasks.
Trade Offs: Not ideal for multi-step problem solving or complex instruction following. Superseded by Gemini 3 Flash for most use cases.
Mistral Large 3 (Mistral)
Description: Mistral’s 675B parameter flagship model with strong multilingual capabilities.
Strengths: Strong reasoning and analytical capabilities. Excellent multilingual support. Open weight flexibility for customization and deployment.
Trade Offs: May not match top frontier models on the most demanding tasks. Performance varies by domain.
Kimi K2.5 (Moonshot)
Description: Advanced open weight model that excels in using tools.
Strengths: Excellent tool usage capabilities. Good for applications requiring API integrations. Strong technical reasoning.
Trade Offs: May be specialized for tool use rather than general conversation. Performance varies on creative tasks.
DeepSeek R1 (DeepSeek)
Description: Open-source model designed for efficiency.
Strengths: Cost-effective and efficient. Good for applications where budget is a primary concern. Open-source flexibility.
Trade Offs: May not match performance of frontier models on complex tasks. Limited compared to more advanced models.
Llama 4 Maverick (Meta)
Description: Advanced open-weight model for reasoning, math, and general knowledge.
Strengths: Strong reasoning capabilities for math and general knowledge. Open weight benefits. Good performance across diverse tasks.
Trade Offs: Not as fast as smaller models. May require more specific prompting for best results.
Llama 4 Scout (Meta)
Description: Powerful for multi-document analysis, cross-lingual understanding, and context-aware reasoning.
Strengths: Excellent at analyzing multiple documents simultaneously. Strong cross-lingual capabilities. Advanced contextual understanding.
Trade Offs: May be slower for simple tasks. Specialized for document analysis rather than general usage.
Llama 3.3 70B Instruct (Meta)
Description: Advanced model for reasoning, math, and general knowledge.
Strengths: Strong general well balanced use cases. Performs well in math. Effective at following clear instructions. Open weight flexibility.
Trade Offs: Slower than smaller models. Does not follow instructions as well as Claude/GPT models.
Qwen 3 (Alibaba)
Description: Large-scale Qwen3 model with 235B parameters, optimized for instruction following and reasoning tasks.
Strengths: Excellent multilingual support. Strong performance on reasoning and instruction following tasks. Good balance of performance and efficiency. Open weight flexibility.
Trade Offs: May not match frontier model performance on highly specialized tasks. Performance varies depending on language and domain.
Tips for Selecting the Right Model
Selecting can be tricky. That’s why we encourage you to play and experiment as you build to find the model that is best fit for your context.Selection Considerations
Ask yourself what is an ideal response time for your app?
Ask yourself what is an ideal response time for your app?
Identify what complexity level is your task?
Identify what complexity level is your task?
What is the level of accuracy you are requiring of your app?
What is the level of accuracy you are requiring of your app?
Do you need open weights or source code access?
Do you need open weights or source code access?
Best Practices
Try to match your model with your use case:
Try to match your model with your use case:
Test out multiple models for apps that you are building:
Test out multiple models for apps that you are building:
Additional best practices:
Additional best practices:
FAQ
Will switching models affect my existing app?
Will switching models affect my existing app?
How do I know which model is best for my specific use case?
How do I know which model is best for my specific use case?
Can I use different models for different parts of my app suite?
Can I use different models for different parts of my app suite?
When should I choose Claude Opus 4.6 vs Claude Sonnet 4.6 vs Claude Haiku 4.5?
When should I choose Claude Opus 4.6 vs Claude Sonnet 4.6 vs Claude Haiku 4.5?
What's the difference between GPT 5.2 and GPT-5 Mini?
What's the difference between GPT 5.2 and GPT-5 Mini?
What's the difference between frontier, open weight, and open source models?
What's the difference between frontier, open weight, and open source models?
When should I consider open weight models like Llama 4, Qwen 3, Mistral Large 3, or DeepSeek R1?
When should I consider open weight models like Llama 4, Qwen 3, Mistral Large 3, or DeepSeek R1?
We Want Your Feedback!
Last updated: 03/02/2026